SEKE: Specialised Experts for Keyword Extraction
Matej Martinc, Hanh Thi Hong Tran, Senja Pollak, Boshko Koloski
Findings of the Association for Computational Linguistics: EMNLP 2025
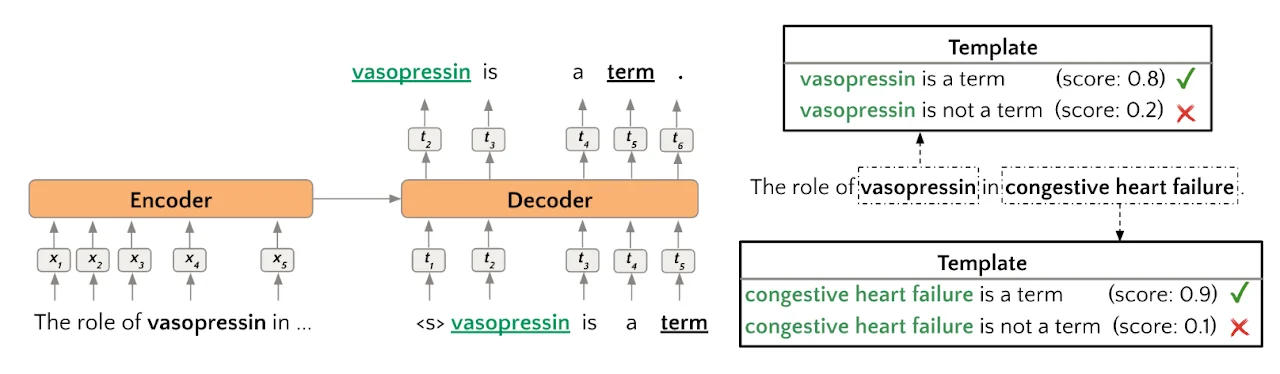
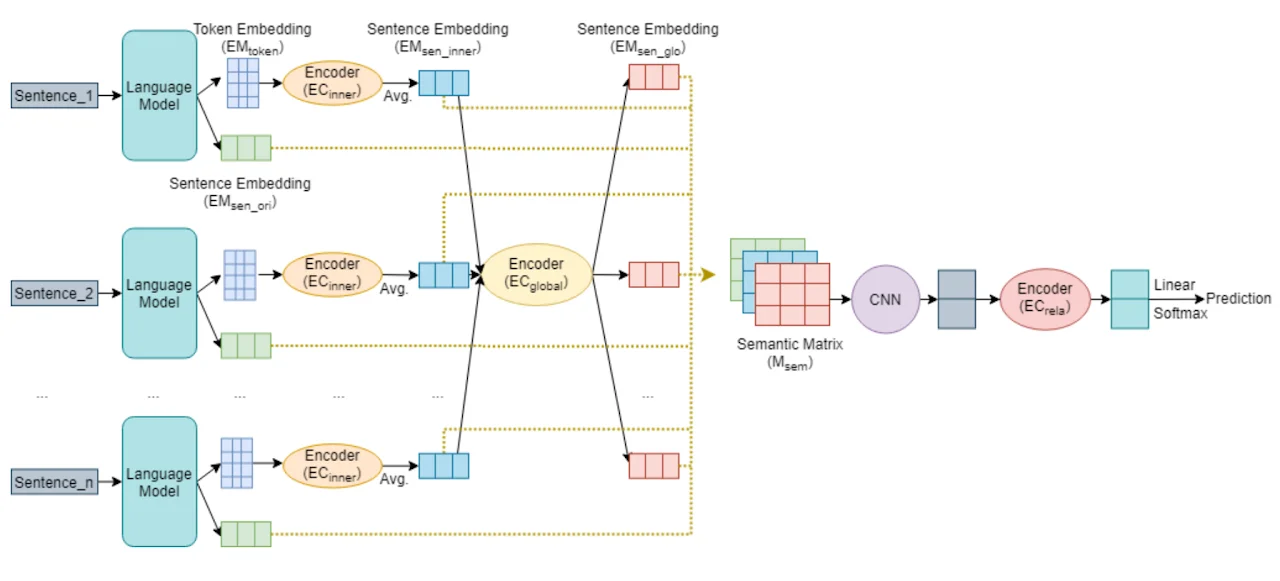
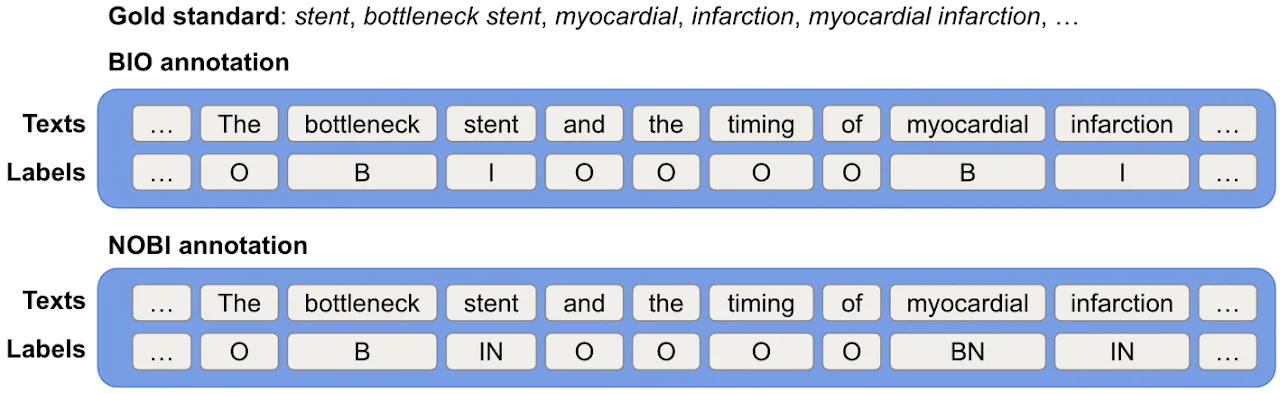
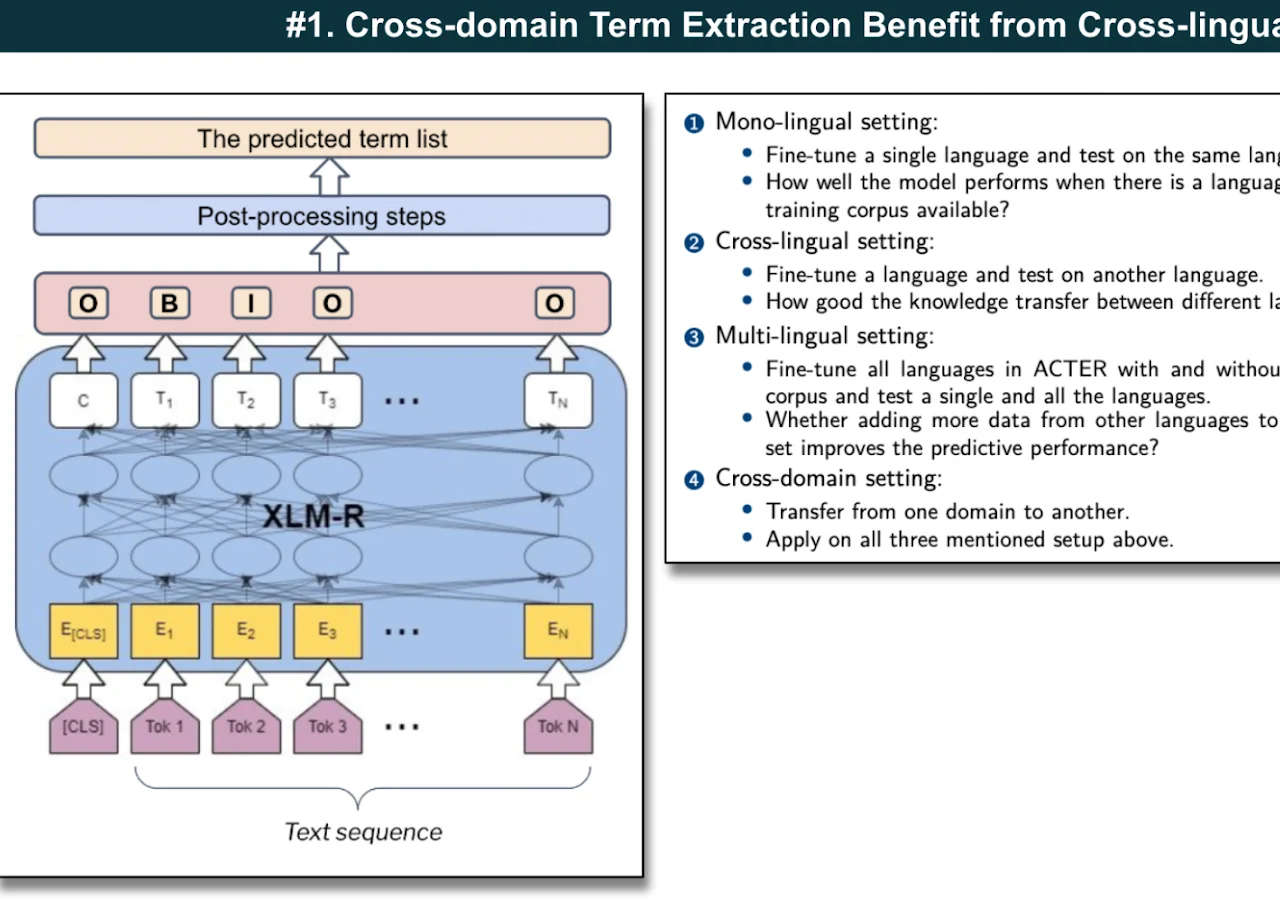
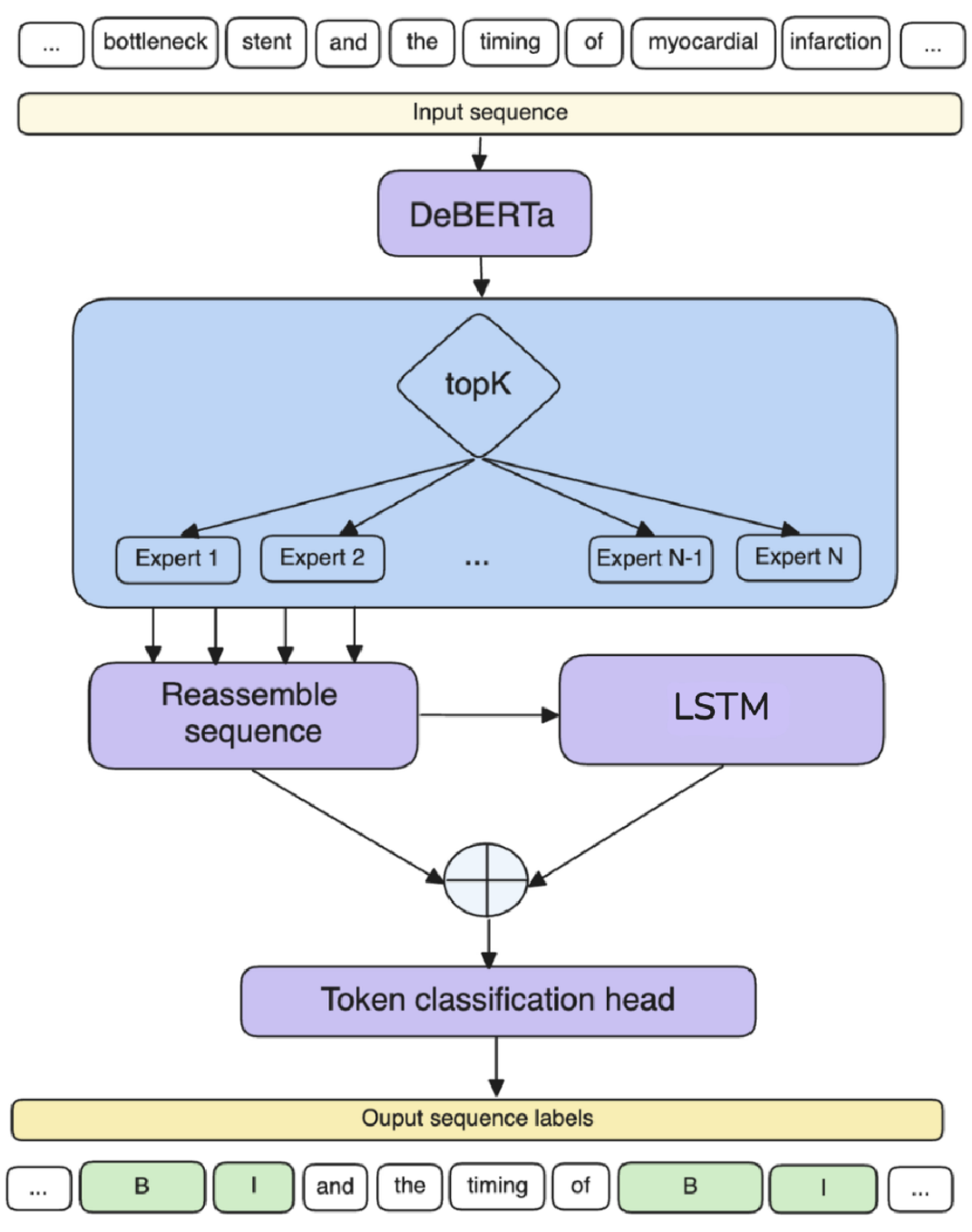
We propose a novel supervised keyword extraction approach based on the mixture of experts (MoE) technique. MoE uses a DeBERTa as the backbone model and builds on the MoE framework, where experts attend to each token, by integrating it with a bidirectional Long short-term memory (BiLSTM) network, to allow successful extraction even on smaller corpora, where specialisation is harder due to lack of training data. The MoE framework also provides an insight into inner workings of individual experts, enhancing the explainability of the approach.